
Getting Ready for a Massively Parallel World
In this article, I start with a problem, show a single-threaded solution, and evolve the solution into one that will take advantage of as many processor cores as are available. I use C# and the .NET Task Parallel Library (TPL) for sample code.
The Problem
The problem is to recursively walk a directory structure and build a dictionary of MD5 hashes of the contained files, indexed by their full path and filenames.
Classical Depth-First Solution
My first solution is straightforward. It recurses into any subdirectories first, then calculates the hashes of the files in the current directory. The caller creates a FileSet dictionary before calling the function, and passes it in by reference. This dictionary is passed along to each recursive call.
// For all the examples: a dictionary of hashes indexed by filenames.
using FileSet = Dictionary<string, string>;
// Recursively walk a directory structure and create a dictionary of MD5
// hashes of all files, indexed by filename. Caller specifies the root.
static void GetFileHashesSerial(DirectoryInfo root, ref FileSet fileHashes)
{
// Get all subdirectories of this directory.
DirectoryInfo[] subDirs = root.GetDirectories();
// Recurse into each subdirectory of this directory.
foreach (DirectoryInfo dirInfo in subDirs)
{
GetFileHashesSerial(dirInfo, ref fileHashes);
}
// Now, process all the files in this directory.
FileInfo[] files = root.GetFiles("*");
foreach (FileInfo file in files)
{
fileHashes.Add(file.FullName, Md5.GetMd5HashFromFile(file.FullName));
}
}
Multithreaded Part 1
An easy target for parallelization in this function is the second for loop, where the hash of each file is calculated and added to the dictionary. Using the TPL, we create a task for each hash operation, and put the results into an array. After the for loop, on the main thread, we iterate over the array, and add the results to the dictionary. If we try to access a task result in the array and the task has not completed yet, the main thread will block until the result is ready. When the loop is complete, all the tasks will have completed, and the results will be in the dictionary. I am giving this function a new name to distinguish it from the last.
// Recursively walk a directory structure and create a dictionary of MD5
// hashes of all files, indexed by filename. Caller specifies the root.
static void GetFileHashesParallelFiles(DirectoryInfo root, ref FileSet fileHashes)
{
// Get all subdirectories of this directory.
DirectoryInfo[] subDirs = root.GetDirectories();
// Recurse into each subdirectory of this directory.
foreach (DirectoryInfo dirInfo in subDirs)
{
GetFileHashesParallelFiles(dirInfo, ref fileHashes);
}
// Now, process all the files in this directory.
FileInfo[] files = root.GetFiles("*");
// The task will return a key-value pair to put into fileHashes.
Task<KeyValuePair<string, string>>[] taskFilesArray =
new Task<KeyValuePair<string, string>>[files.Length];
int fileNo = 0;
foreach (FileInfo file in files)
{
taskFilesArray[fileNo++] =
Task<KeyValuePair<string, string>>.Factory.StartNew(() =>
new KeyValuePair<string, string>(file.FullName, Md5.GetMd5HashFromFile(file.FullName)));
}
// Merge the results of the file tasks with fileHashes, which
// already has the results from the subdirectories.
foreach (Task<KeyValuePair<string, string>> task in taskFilesArray)
{
// Accessing each array item blocks until the task is finished.
fileHashes.Add(task.Result.Key, task.Result.Value);
}
}
Multithreaded Part 2
There is one more opportunity for parallelization in this function: the recursive calls to do the work in the subdirectories. This is harder because we are passing around the dictionary, and for this to work, we would need to synchronize access to it to make it thread-safe. To solve this, we borrow an idea from functional programming: instead of mutating the state of the dictionary parameter, change the function to create and return new state. Then, the function can collect all the newly created dictionaries returned by the recursive calls and merge them once all the asynchronous work is complete. In this version, the caller does not create a dictionary to pass in, but uses the dictionary returned by the function. Again, using a new name for the function, this is the final version:
// Recursively walk a directory structure and create a dictionary of MD5
// hashes of all files, indexed by filename. Caller specifies the root.
static FileSet GetFileHashesParallelFilesAndDirs(DirectoryInfo root)
{
FileSet fileHashes = new FileSet();
// Get all subdirectories of this directory.
DirectoryInfo[] subDirs = root.GetDirectories();
Task<FileSet>[] taskDirsArray = new Task<FileSet>[subDirs.Length];
// Start a background task for each recursive call into a
// subdirectory.
int dirNo = 0;
foreach (DirectoryInfo dirInfo in subDirs)
{
taskDirsArray[dirNo++] = Task<FileSet>.Factory.StartNew(()
=> GetFileHashesParallelFilesAndDirs(dirInfo));
}
// Now, process all the files in this directory.
FileInfo[] files = root.GetFiles("*");
// The task will return a key-value pair to put into fileHashes.
Task<KeyValuePair<string, string>>[] taskFilesArray =
new Task<KeyValuePair<string, string>>[files.Length];
int fileNo = 0;
foreach (FileInfo file in files)
{
taskFilesArray[fileNo++] =
Task<KeyValuePair<string, string>>.Factory.StartNew(() =>
new KeyValuePair<string, string>(
file.FullName, Md5.GetMd5HashFromFile(file.FullName)));
}
// Merge the results of the file tasks.
foreach (Task<KeyValuePair<string, string>> task in taskFilesArray)
{
// Accessing each array item blocks until the task is finished.
fileHashes.Add(task.Result.Key, task.Result.Value);
}
// Now merge the results from the subdirs with the results from the
// files from this directory.
foreach (Task<FileSet> task in taskDirsArray)
{
// Accessing each array item blocks until the task is finished.
task.Result.ToList().ForEach(x => fileHashes.Add(x.Key, x.Value));
}
return fileHashes;
}
Performance Measurements
I ran each of these algorithms over a sample directory tree and measured the time to complete each one. As expected, the first version is the slowest, the second is faster, and the third is the fastest. I ran the test multiple times, and while the times varied slightly, the following results are typical:
- GetFileHashesSerial: 5.8 sec
- GetFileHashesParallelFiles: 2.5 sec
- GetFileHashesParallelFilesAndDirs: 1.7 sec
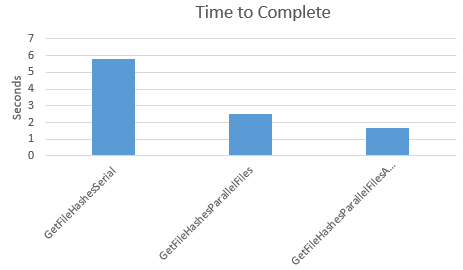
My test machine has 8 cores and slow disk I/O. The test data has a low level of directory nesting, with about 1300 files in 29 directories, and an average size of about 850KB. All of these variables will have an effect on outcome of a specific test instance, but the performance ranking of the algorithms should remain constant.
Conclusion
As the number of processors continues to increase, we developers will need to adjust our thinking to take advantage of them. If we think in terms of function programming and use state generation instead of state mutation, parallelization becomes easier because we don't have to synchronize thread access to shared mutable state. In this example, I lean on the TPL to abstract away the details about threading and the number of processors on the target machine. All I have to do express the tasks that I want to run in parallel, and the TPL takes care of the rest. I could run the final version of this program as-is on a PC with 1300 processors, and in theory, it could take advantage of them all.